



核心优势

概率计算
速度优于经典算法 100 倍
精度较于经典算法提升 150%
✓ 真随机
✓ 更低能耗
✓ 更快收敛
✓ 更少晶体管
问题规模
1024 bit 节点 / 变量问题
精度可达到 16 bit
运行条件
可在室温条件下稳定运行
无需量子超低温
兼容性
CMOS / PCIe 兼容
稳定、可扩展
多种接入模式
底层控制驱动 SDK + API
上层软件开发工具包

云计算服务 + 平台
速度优于经典算法 100 倍
精度较于经典算法提升 150%
概率计算 + 解决方案
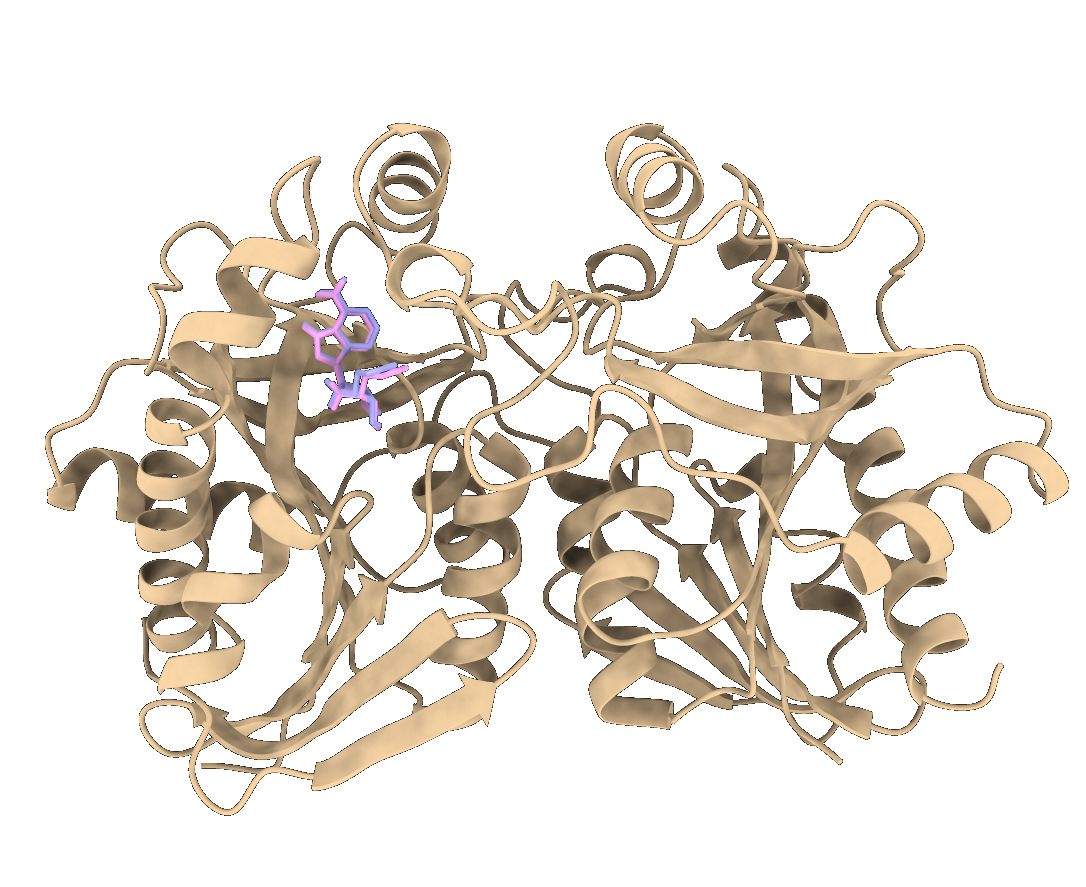
1y6r 蛋白质和 MTM 小分子对接
RMSD 均可达到约 ~0.5 ( ±0.1 )
~12.47s
~0.775s
<0.XXXs
CPU
SpinPU-M01
SpinPU-M02
SpinPU-M02 的相关数据暂未披露,敬请关注
分子对接速度对比
分子对接是分子模拟的重要方法之一,其本质是两个或多个分子之间的识别过程,其过程涉及分子之间的空间匹配和能量匹配。分子对接方法在药物设计、材料设计等领域有广泛的应用。
合作伙伴













北京大学
应用磁学中心
北京大学
凝聚态物理与材料研究所
北京大学
威海海洋研究院
联系我们
有疑问吗?我们随时为您提供帮助。
联系寒序
我们随时为您提供帮助。请填写表单或发送电子邮件或拨打电话。
+86 133-8209-9521
商务合作:office@icy.tech
求职招聘:hr2024@icy.tech
其他咨询:info@icy.tech
北京市海淀区中关村东路 8 号东升大厦 A 座
北京市海淀区北京大学物理学院应用磁学中心